Read in a File and Find Character Frequency C++
Read a text file and do frequency assay by using PowerShell
![]()
Dr Scripto
Summary: Acquire how to read a text file and practise a letter-frequency assay using Windows PowerShell in this article written by the Microsoft Scripting Guy, Ed Wilson.
This is the third mail service in a multi-part series of blog posts that deal with how to make up one's mind letter frequency in text files. To fully sympathize this post, y'all should read the entire series in society.
Here are the posts in the series:
- Letter frequency analysis of text by using PowerShell
- How to skip the first and ending of a file with PowerShell
- Read a text file and do frequency analysis by using PowerShell
- Compare the letter frequency of two text files by using PowerShell
- Summate pct character frequencies from a text file by using PowerShell
- Boosted resources for text assay by using PowerShell
Today I am going to put the script I wrote yesterday together with the script that I wrote on Friday. After I do that, I will be able to get a more accurate letter-frequency analysis of a text file. The code that I wrote the other day reads a text file by using the Get-Content cmdlet. Then I bring together the strings together then that I can have a single string to parse. I then catechumen the script to all majuscule, go the enumerator, grouping my results, and sort my results.
So, first of all, here is the basic alphabetic character-frequency analysis code that I wrote the other twenty-four hour period:
$a = Get-Content C:\fso\ATaleOfTwoCities.txt $a.Count $ajoined = $a -join "`r" $ajoinedUC = $ajoined.ToUpper() $ajoinedUC.GetEnumerator() | grouping -NoElement | sort count -Descending
Put the script together
The first thing I do is copy the code to a bare page in my Windows PowerShell integrated scripting environment (ISE). This is shown here:
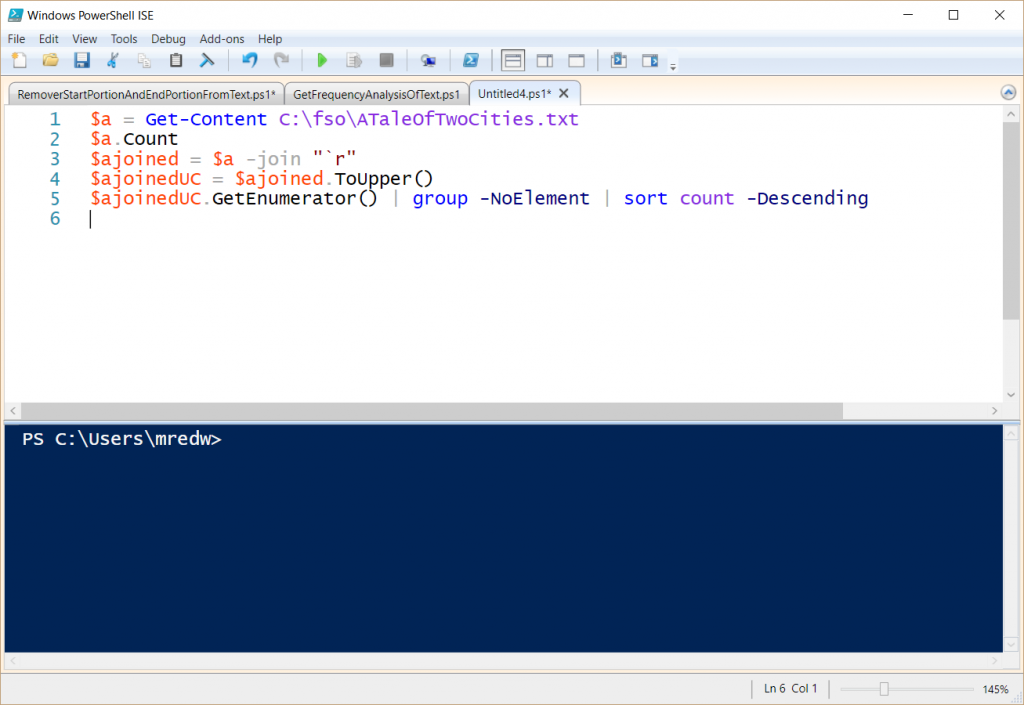
Now I need to take the lawmaking that I wrote yesterday. This code removes the beginning and catastrophe portions of the text file.
$a= Go-Content 'C:\fso\MobyDick.txt'
$array = @() for ($i = 0; $i -lt $a.Count; $i++) { If ($a[$i] -cmatch 'Beginning') {$assortment +=$i } If ($a[$i] -like "Finish of *Project*") {$array += $i } }
$get-go = $array[0] +7 $end = $assortment[one] -ane $a[$commencement .. $end]
This script likewise reads the text file. It so creates an empty array, loops through the text, and looks for start and finish strings. Information technology then saves the line numbers that it finds so that I can utilise assortment note to render a range of text from the file.
I paste this code at the beginning of my new script folio because I need to grab the correct text Earlier I convert information technology all to a single line of text, convert it to capital letter, and count the messages. So, at this point, my script appears as shown here:
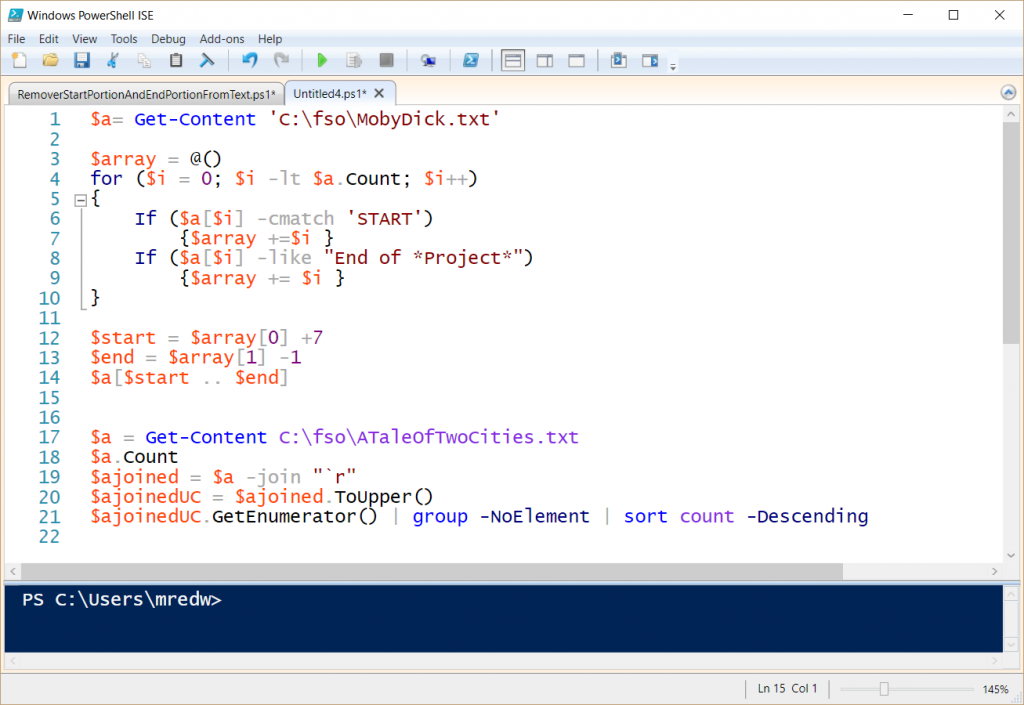
Make clean up the code
Well, there are some redundancies. The code as it stands is shown here:
$a= Get-Content 'C:\fso\MobyDick.txt'
$array = @() for ($i = 0; $i -lt $a.Count; $i++) { If ($a[$i] -cmatch 'Offset') {$array +=$i } If ($a[$i] -like "Stop of *Projection*") {$array += $i } }
$start = $array[0] +seven $end = $array[1] -1 $a[$start .. $stop]
$a = Get-Content C:\fso\ATaleOfTwoCities.txt $a.Count $ajoined = $a -join "`r" $ajoinedUC = $ajoined.ToUpper() $ajoinedUC.GetEnumerator() | group -NoElement | sort count -Descending
So, the obvious duplication is the 2nd Get-Content line. I delete information technology, and my script is shown here:
$a= Become-Content 'C:\fso\MobyDick.txt'
$array = @() for ($i = 0; $i -lt $a.Count; $i++) { If ($a[$i] -cmatch 'Showtime') {$array +=$i } If ($a[$i] -like "Finish of *Project*") {$array += $i } }
$start = $array[0] +7 $end = $array[i] -1 $a[$start .. $end]
$a.Count $ajoined = $a -join "`r" $ajoinedUC = $ajoined.ToUpper() $ajoinedUC.GetEnumerator() | group -NoElement | sort count -Descending
The side by side affair I need to do is to delete the $a.count line because I do not need it either. The script now is shown here:
$a= Get-Content 'C:\fso\MobyDick.txt'
$array = @() for ($i = 0; $i -lt $a.Count; $i++) { If ($a[$i] -cmatch 'First') {$array +=$i } If ($a[$i] -like "End of *Project*") {$array += $i } }
$kickoff = $array[0] +seven $end = $array[ane] -1 $a[$commencement .. $terminate]
$ajoined = $a -join "`r" $ajoinedUC = $ajoined.ToUpper() $ajoinedUC.GetEnumerator() | grouping -NoElement | sort count -Descending
The last thing I need to exercise is to store the result of grabbing my text from assortment notation. So that I do not need to modify my copied frequency code, I simply shop the $a[$kickoff ... $end] code back into the $a variable. This revised line is shown here:
$a = $a[$start .. $end]
The entire script is shown here:
$a= Get-Content 'C:\fso\MobyDick.txt'
$array = @() for ($i = 0; $i -lt $a.Count; $i++) { If ($a[$i] -cmatch 'Offset') {$array +=$i } If ($a[$i] -like "End of *Project*") {$assortment += $i } }
$start = $array[0] +7 $end = $array[ane] -1 $a = $a[$starting time .. $finish]
$ajoined = $a -bring together "`r" $ajoinedUC = $ajoined.ToUpper() $ajoinedUC.GetEnumerator() | group -NoElement | sort count -Descending
The script is shown hither in the ISE:
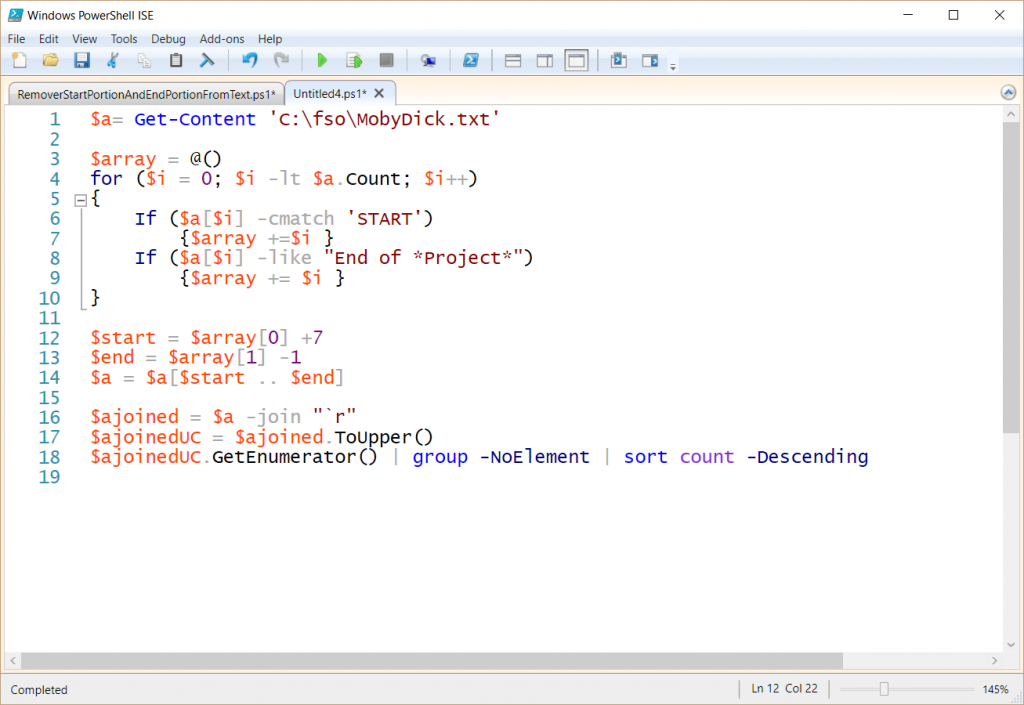
The output from this script is shown here:
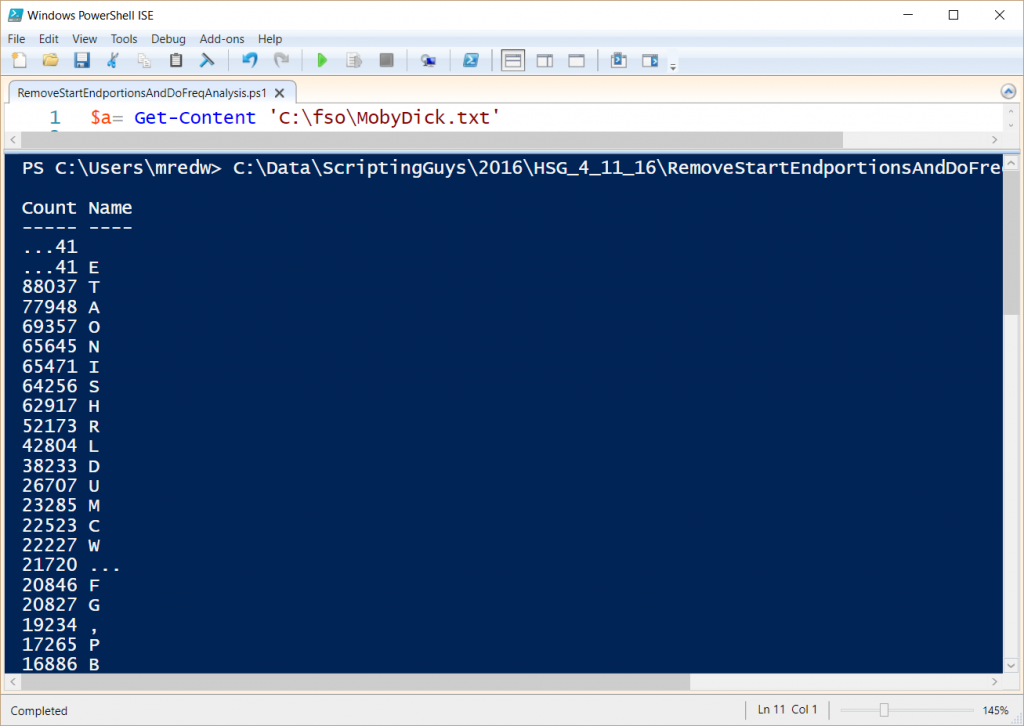
I invite yous to follow me on Twitter and Facebook. If you take any questions, send electronic mail to me at scripter@microsoft.com, or mail your questions on the Official Scripting Guys Forum. Also cheque out my Microsoft Operations Direction Suite Blog. See you tomorrow. Until then, peace.
Ed Wilson Microsoft Scripting Guy
![]()
griffithhielf1963.blogspot.com
Source: https://devblogs.microsoft.com/scripting/read-a-text-tile-and-do-frequency-analysis-using-powershell/
Post a Comment for "Read in a File and Find Character Frequency C++"